Algroveon-News – RSS-Nachrichten lokal lesen, ohne Tracking
Warum ich meinen eigenen Nachrichten-Feed gebaut habe: RSS ohne Tracking, bevorzugte Feeds, mit eigener KI-Zusammenfassung – lokal und unter vollständiger Kontrolle.
Zusammenfassung
Algroveon-News ermöglicht das lokale Lesen von RSS-Feeds ohne externe Algorithmen oder Tracking. Das Tool bietet KI-gestützte Zusammenfassungen und gibt Nutzern die volle Kontrolle über ihre kuratierten Nachrichtenquellen zurück.
Diese Zusammenfassung wurde mit KI-Unterstützung erstellt.
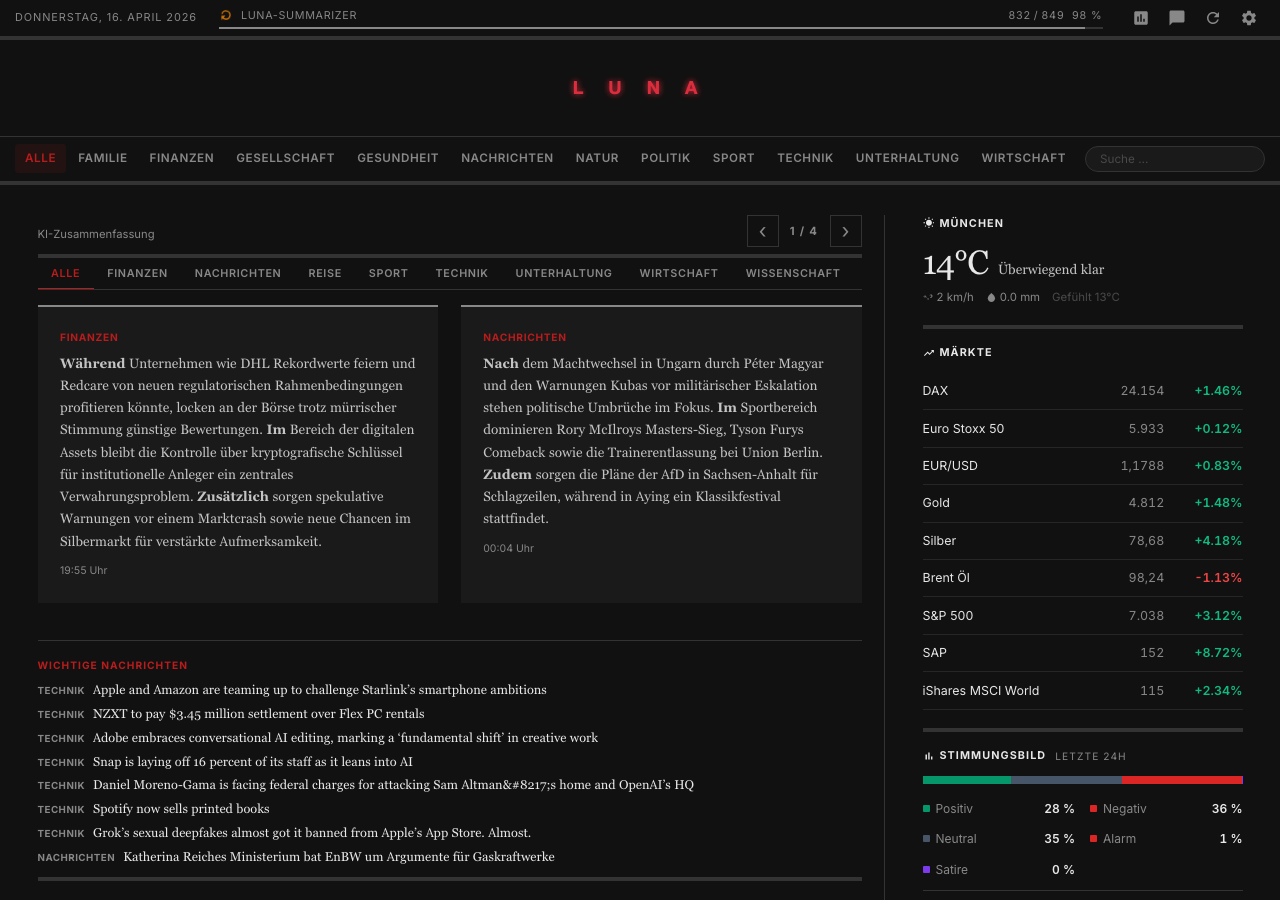
Nachrichtenmanagement statt Nachrichtenflut
Eine tägliche Übersicht über das Nachrichtengeschehen ist nichts Besonderes. Dafür gibt es mehr als genug Apps und Aggregatoren. Das Problem ist nur: Am Ende bestimmen sie, was oben landet und was untergeht.
Genau das hat mich gestört. Ich wollte keine News-App, die Relevanz über ihren eigenen Algorithmus definiert. Ich wollte eine eigene kuratierte Nachrichtenseite auf Basis meiner persönlichen Quellen. Eine Oberfläche, in der nicht irgendeine Plattform entscheidet, welche Themen hochgespült werden, sondern ich selbst. Mir ist dabei bewusst, dass ich meinen Korridor damit zunächst auch selbst enger ziehe, weil ich die Quellen auswähle. Mehr Diversität soll in späteren Schritten dazukommen – aber noch nicht heute.
RSS ist dafür der richtige Ausgangspunkt – direkte Quellen, volle Kontrolle. Aber RSS hat eben auch eine Grenze: Es aggregiert, aber es filtert nicht wirklich. Wer zwanzig Feeds abonniert, hat schnell hundert Artikel pro Tag vor sich, zehn davon zum selben Ereignis aus zehn verschiedenen Quellen, ohne dass sofort klar ist, welcher davon Substanz hat.
Das war der eigentliche Ausgangspunkt von Algroveon-News: keine fremde Gewichtung, keine Black-Box-Logik, keine externe Entscheidungshoheit, sondern meine eigene kuratierte Nachrichtenansicht – automatisch zusammengefasst, nach Qualität bewertet und über Zeit hinweg analysierbar. Vollständig lokal und auf Basis genau der Quellen, die ich bewusst ausgewählt habe.
Warum kein fertiges System
Die Alternativen wurden ernsthaft geprüft. Miniflux, FreshRSS, feeds.fun – alle haben ihre Stärken. Aber keines passt wirklich zu dem, was hier entstehen sollte:
| Kandidat | Problem |
|---|---|
| Miniflux | Go + PostgreSQL, kein LLM, kein Scoring, zu viel Infrastruktur |
| FreshRSS | PHP, falscher Stack, keine Erweiterbarkeit in die gewünschte Richtung |
| feeds.fun | Kein lokales LLM, kein REST-API für Algroveon-Agent |
| Kommerzielle Apps | Tracking, Algorithmen, Cloud-Pflicht |
Fertige Systeme bringen immer ihren eigenen Rahmen mit: Deployment, Updates, Abhängigkeiten, Einschränkungen. Genau das wollte ich hier nicht. Was ich gebraucht habe, war kein fertiges System, sondern eine Sammlung sauberer Bausteine. FastAPI, SQLite, httpx, HTMX – Dinge, die ich verstehe, kontrollieren und bei Bedarf selbst anpassen kann.
Algroveon-Parser als eigene Grundlage
Die wichtigste Architekturentscheidung war: das Feed-Parsing zuerst auszulagern und dafür eine eigene Grundlage zu bauen.
Die naheliegende Alternative wäre feedparser gewesen – die etablierte Python-Library.
Das hätte Zeit gespart, aber auch eine Abhängigkeit ins Fundament gezogen, die ich nur
begrenzt kontrollieren kann. feedparser bringt eigene Logik für HTTP, Encodings und Fehlerbehandlung
mit. Genau an solchen Stellen wird es mühsam, wenn ein Feed sich plötzlich unerwartet
verhält und man Fehler nicht mehr sauber eingrenzen kann.
Die Entscheidung fiel deshalb auf eine eigene Library: algroveon-parser, ohne externe
Dependencies, in einem separaten Repo mit eigenen Tests. Drei Wochen Arbeit, 16 echte
Feed-Fixtures als Testsuite. Das Ergebnis ist ein Parser, der genau das macht, was nötig
ist – nicht mehr und nicht weniger. Jeder Encoding-Fallback, jeder Namespace und jeder
Datums-Edge-Case ist nachvollziehbar, dokumentiert und testbar.
Diese Trennung war im Rückblick richtig. algroveon-parser steckt heute auch in algroveon-agent.
Eine gemeinsame, getestete Parsing-Schicht für mehrere Projekte ist am Ende deutlich mehr
wert als die kurzfristig gesparte Zeit.
Weitere Abhängigkeiten, die ersetzt wurden
feedparser war nicht der einzige Kandidat, der am Ende rausgeflogen ist. Dieselbe Logik
wurde auch auf andere externe Libraries angewendet:
| Kandidat | Entscheidung | Begründung |
|---|---|---|
APScheduler |
Ersetzt | ~20 Zeilen asyncio-Loop reichen vollständig |
yfinance |
Ersetzt | Inoffizieller Yahoo-Wrapper, bricht regelmäßig; ~30 Zeilen httpx |
| HTMX via CDN | Self-hosted | Kein externer Request, kein Supply-Chain-Risiko |
| Inter-Font via CDN | Self-hosted | Gleicher Grund – alles liegt in static/, eingecheckt in Git |
Das Ergebnis: Algroveon-News macht im Betrieb keinen einzigen Request an externe Infrastruktur außer an die abonnierten Feeds selbst.
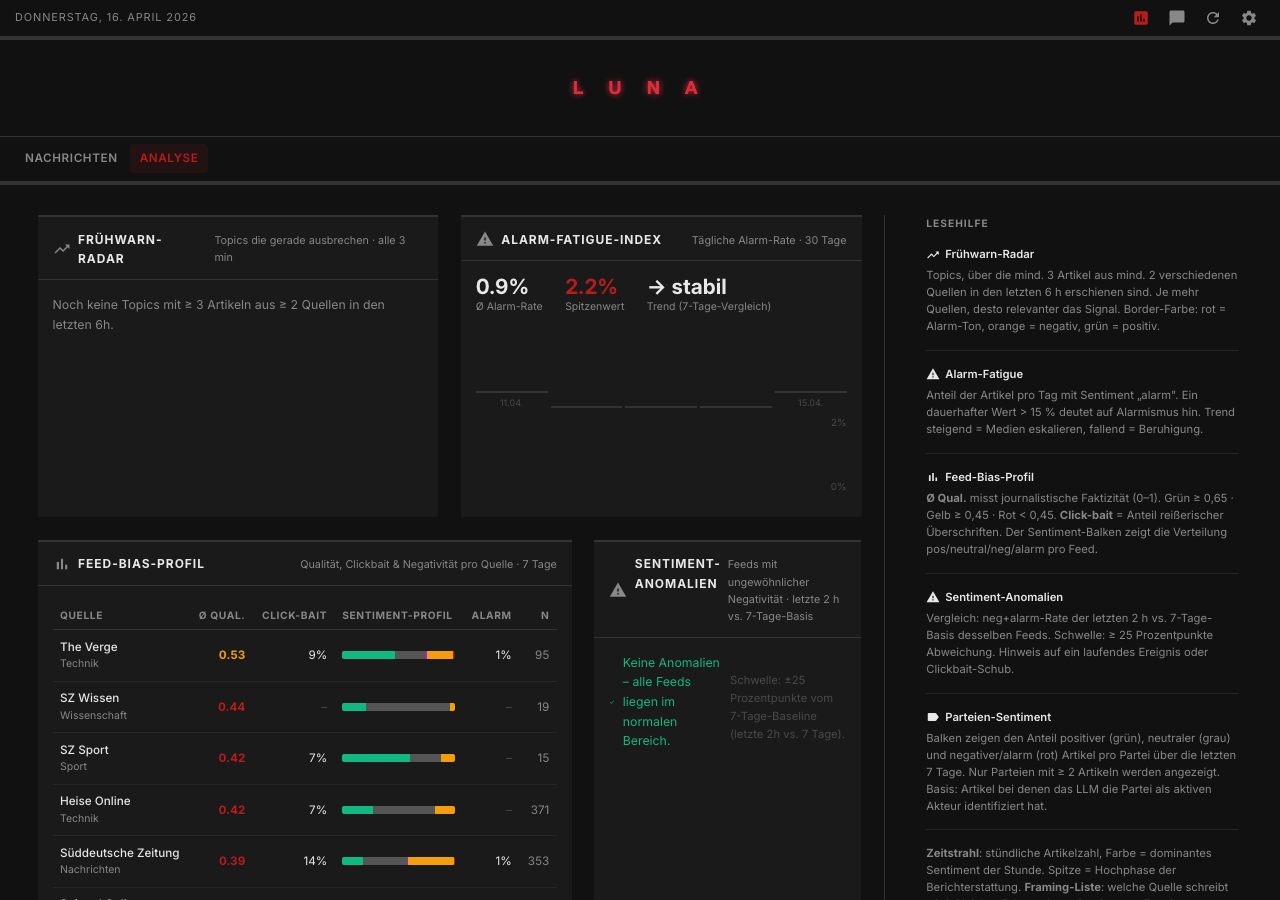
Der Scoring-Ansatz: Redaktionsleitlinien statt Black Box
Das Herzstück von Algroveon-News ist der Scorer. Jeder Artikel wird einmalig durch ein lokal laufendes LLM bewertet und bekommt drei Eigenschaften:
- Sentiment: positiv / neutral / negativ / alarm / satire
- Qualität: 0–1 (0 = Clickbait oder substanzlos, 1 = journalistisch gehaltvoller Artikel)
- Clickbait: true / false
Das klingt zunächst nicht unähnlich zu vielen anderen LLM-Systemen. Der Unterschied liegt für mich aber in der Grundlage: Die Bewertungslogik steckt nicht in irgendeinem Prompt, der still im Code liegt und sich irgendwann unbemerkt verändert. Sie steckt in einer eigenen Prompt-Datei (algroveon_news/resources/redaktions_prompt.txt).
Die Analyse-Features
Über das Scoring hinaus gibt es fünf Analyse-Features, die Algroveon-News von einem einfachen Aggregator unterscheiden:
Narrativ-Tracking
Wie entwickelt sich ein Thema über acht Wochen? Das Narrativ-Tracking zeichnet für jedes Topic die Sentiment-Verteilung über die Zeit auf: wie viele Artikel waren positiv, neutral, negativ. Dadurch werden Muster sichtbar, die man beim normalen Lesen leicht übersieht – etwa ein Thema, das über Wochen eher neutral behandelt wurde und dann plötzlich kippt, oder eines, das auf einmal vermehrt "alarm"-Artikel produziert.
Stille-Alarm
Manchmal ist die interessanteste Nachricht nicht eine Schlagzeile, sondern ihr Ausbleiben. Der Stille-Alarm erkennt Topics, die regelmäßig erschienen sind – mindestens dreimal in 14 Tagen – und seit 48 Stunden nicht mehr auftauchen. Ein stilles, passives Monitoring ohne manuelle Arbeit.
Framing-Vergleich
Dasselbe Ereignis kann je nach Quelle sehr unterschiedlich eingeordnet werden. Das Framing-Feature extrahiert pro Artikel drei Dimensionen: Kern-Aussage, Framing-Typ (kritisch / neutral / alarmierend / positiv / konstruktiv) und implizierte Ursache. Beim Aufklappen eines Topics sieht man nebeneinander, wie etwa Spiegel, Tagesschau und Handelsblatt denselben Sachverhalt rahmen. Kein Faktencheck – aber ein sehr brauchbares Werkzeug, um Perspektivunterschiede sichtbar zu machen.
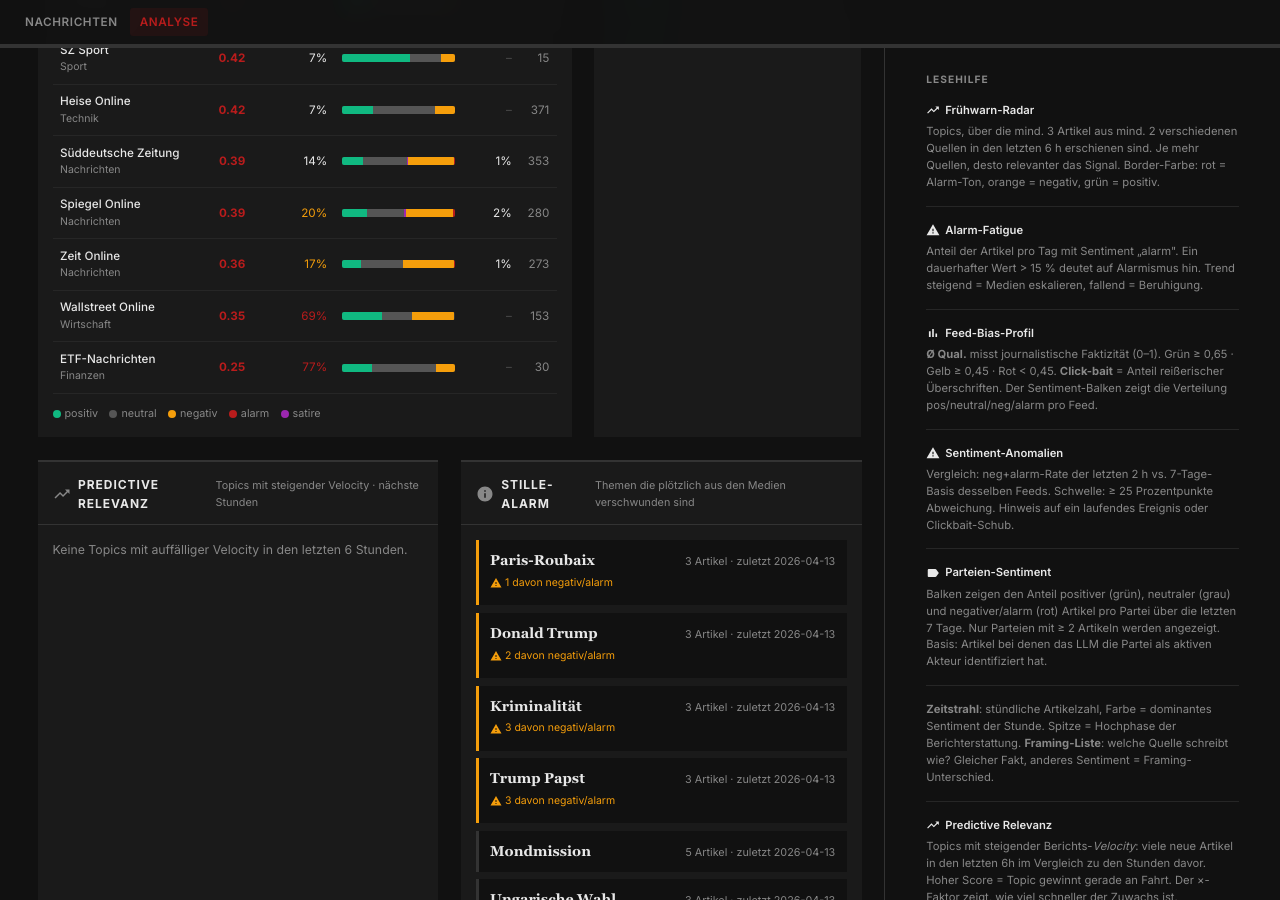
Argumentkarten
Bei Themen mit gemischtem Sentiment – also dann, wenn die Berichterstattung nicht klar in eine Richtung läuft – synthetisiert das Modell aus den vorliegenden Artikeln strukturierte Pro/Kontra-Listen. Keine eigene Meinung, keine künstliche Ausgewogenheit, sondern nur das, was die Quellen an Argumenten tatsächlich hergeben.
Mini-RAG
Fragen an die eigene Nachrichtendatenbank: "Was hat die EZB heute entschieden?" → FTS5-Suche über alle Artikel → relevanteste Treffer als Kontext ans LLM → Antwort mit Quellenangaben. Ein Kontext-Badge zeigt an, ob echte Treffer vorlagen oder ob das Modell ohne ausreichenden Kontext antworten musste. Genau daran trennt sich in der Praxis eine belastbare Antwort von einer Halluzination.
Die Verbindung zu Algroveon-Agent und Algroveon-AI
Algroveon-News ist kein isoliertes Tool. Es ist ein Dienst innerhalb meiner eigenen Infrastruktur. Algroveon-AI stellt die Rechenleistung. Das LLM (Gemma-4 über Ollama) läuft auf dem Heimserver und verarbeitet alle Summarizer-, Scorer- und Analyse-Calls. Algroveon-News macht keinen einzigen LLM-Call an einen externen Anbieter.
Algroveon-Agent ist der Hauptkonsument der REST-API. Wenn morgens ein täglicher E-Mail-Newsletter (Morning-Briefing) generiert wird, fragt Algroveon-Agent Algroveon-News ab – also nicht live die Feeds selbst, sondern die bereits verarbeiteten, zusammengefassten und bewerteten Artikel. Die eigentliche Echtzeit-Aufgabe des Agents beschränkt sich damit auf die Komposition des Briefings und nicht auf Feed-Crawling, Parsing und Summarisierung. Genau daraus ist Algroveon-News überhaupt als eigenständiger Service entstanden.
Technische Entscheidungen im Rückblick
SQLite statt PostgreSQL – für einen privaten Service mit einer überschaubaren Zahl an Feeds und wenigen tausend Artikeln pro Woche ist SQLite vollkommen ausreichend. Eine Datei, kein separater Prozess, einfaches Backup. FTS5 als eingebaute Extension liefert Volltext-Suche ohne zusätzliche Suchinfrastruktur.
HTMX statt SPA-Framework – das Web-Cockpit ist serverseitig gerendert (Jinja2). HTMX liefert reaktive Panel-Updates, ohne dass dafür ein JavaScript-Build-System nötig wird. Jedes Analyse-Panel lädt seinen Inhalt per Fragment-Request mit eigenem Refresh-Intervall. Der Frontend-Code bleibt dadurch sehr schlank.
asyncio-Loop statt APScheduler – die regelmäßigen Tasks sind schlicht genug für eine handgeschriebene asyncio-Schleife. Rund 20 Zeilen, keine zusätzliche Dependency, kein unnötiger Unterbau, kein Update-Risiko durch fremde Breaking Changes.
Was noch in Arbeit ist
Die Topic-Normalisierung ist systematisch das schwierigste Problem. Dasselbe Thema taucht mal zum Beispiel als "EZB-Zinsentscheidung", mal als "ECB rate decision" und mal nur als "Zentralbank" auf. Das Modell normalisiert solche Varianten nicht konsistent. Ein Kanon-Mapping fängt bekannte Muster ab, aber neue Themen rutschen weiterhin durch. Eine wirklich belastbare Normalisierungsstrategie ist hier noch offen.
Auch die Framing-Qualität hängt spürbar vom eingesetzten Modell und von der Länge der
Artikel ab. Kurze Teaser-Texte – und genau davon liefern viele Feeds nur einen Anriss statt
vollständigem content:encoded – ergeben oft keine besonders aussagekräftigen
Framing-Extrakte. Das ist kein Bug des Systems, sondern eine echte Grenze der verfügbaren
Datenbasis.