Algroveon Agent – Developer Diary: How a Local AI Assistant is Created
From the first tool execution to the security architecture: How Algroveon-Agent evolved step-by-step from a simple LLM wrapper into a true local assistant.
Zusammenfassung
The Algroveon Agent acts as a local AI assistant that takes over complex tasks, such as managing emails or files, through the direct execution of tools. By eschewing cloud services and utilizing Ollama, a high level of data privacy and independence is ensured. Development focuses on a robust security model and the precise processing of reasoning models.
Diese Zusammenfassung wurde mit KI-Unterstützung erstellt.
Introduction
The starting point was simple: an AI assistant that is truly useful – not as a chatbot for asking questions, but as a system that gets things done. Emails, calendar, files, shell. Local, without cloud, without monthly costs. What began as a weekend project is today a fully developed system with its own security model, persistent memory, a daily morning briefing, and a native macOS client. This developer diary tells the story of how it came to be.
Phase 1: The first model, the first tool execution
The technical starting point was Ollama. The choice was clear: completely local, no API key, no cloud overhead. The first model was Qwen3 – with built-in reasoning, which is crucial for agentic tasks.
The first milestone was a simple tool execution: a user request → the model recognizes it needs to read a file → returns a JSON tool call → the code executes the tool → the result goes back to the model → the model responds. It feels unexciting when it works. Until it works, it's a lot of debugging.
The biggest early problem: reasoning models output their thoughts in ` blocks. These blocks sometimes contain JSON examples that the tool call parser mistakenly identifies as real tool calls. The solution: thinking blocks must be completely removed before parsing. This is now firmly anchored inextract_tool_calls()`, but it took several broken sessions before the cause became clear.
Phase 2: Security as architecture, not an afterthought
As soon as the agent can perform real actions – writing files, sending emails, executing shell commands – security is no longer an optional feature.
The fundamental decision was: The LLM makes no security decisions. This sounds obvious, but many security approaches in agent systems implicitly delegate decisions to the model ("ask if you are unsure"). That is insufficient.
Instead, an independent policy engine was created with deterministic rules. Four inspection levels in a fixed order: Profile active? → Source tag rule → Tool allowlist → Approval configuration. BLOCKED always overrides APPROVAL_REQUIRED, which always overrides ALLOWED. The model cannot influence this decision.
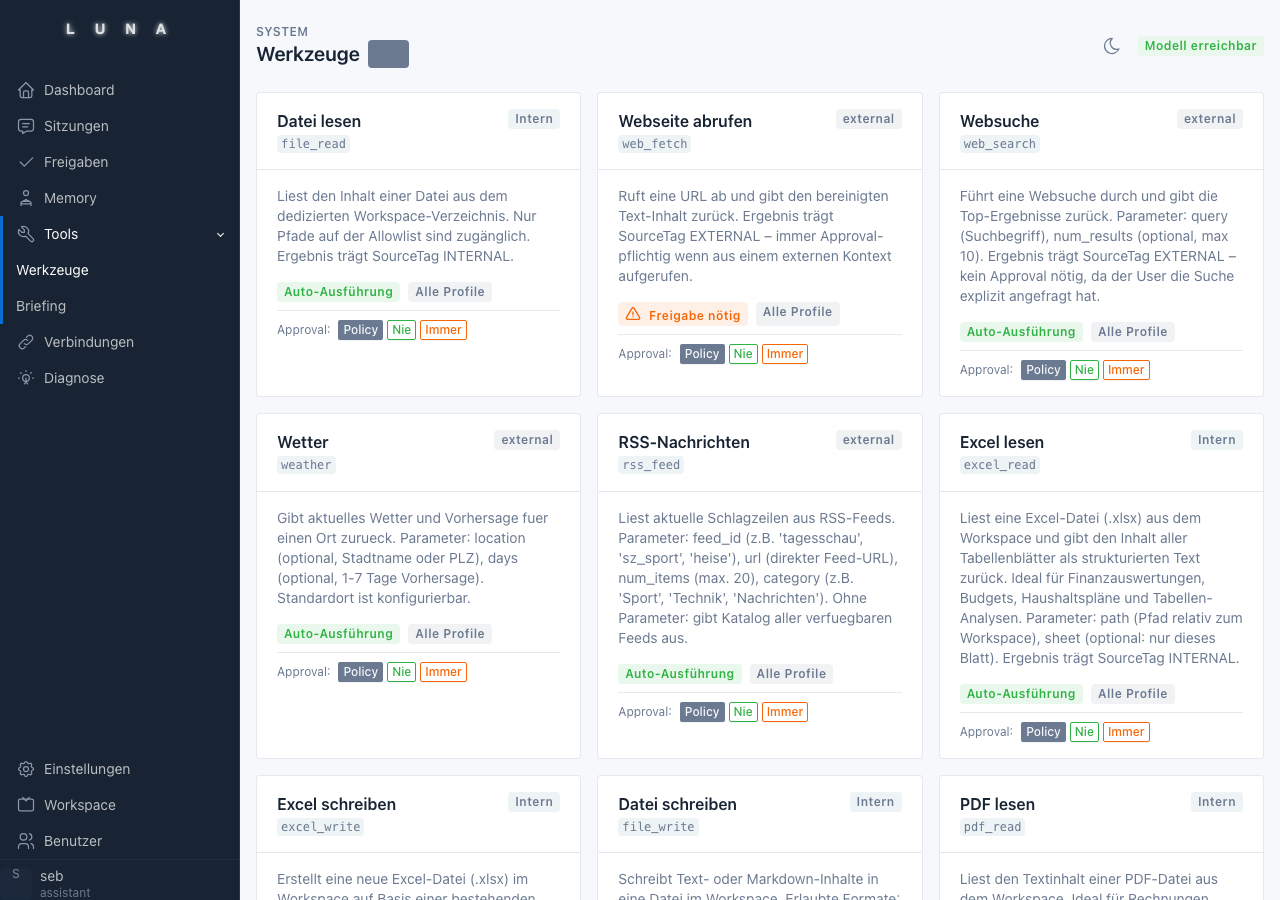
The second pillar of security was the SourceTag system: every data point carries an immutable origin marker. User input is TRUSTED. Tool results from controlled local sources are INTERNAL. Everything from the internet is EXTERNAL. This tag "travels" with the data through the entire system stack. An EXTERNAL-tagged tool response can never write directly to long-term memory – this is not a configuration point, but code logic within the memory engine.
In addition, there is the Approval system: all writing and destructive actions wait for explicit user approval before being executed. Shell, emails, file write access – always approval. From the browser, from the Mac app, from scheduled tasks: the same logic everywhere.
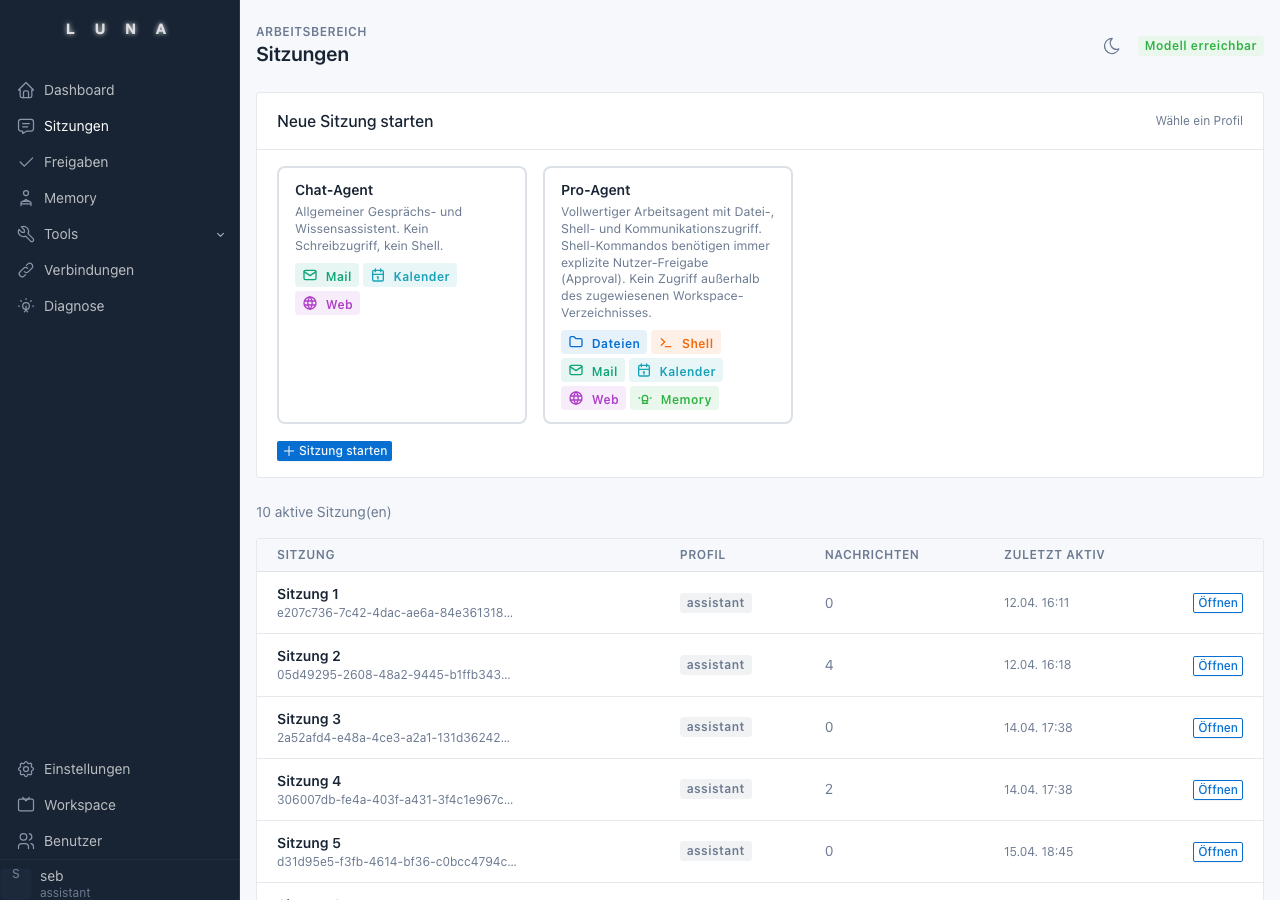
Phase 3: Profiles as operating modes
Not every session needs the same capabilities. The solution: profiles as YAML files that define allowed tools, model selection, and approval behavior.
The profile system evolved iteratively. In the beginning, there were three profiles with manually maintained tool lists. Today there are four, plus the logic that an inactive profile (such as admin) is generally blocked and must be explicitly activated.
What turned out to be correct: each profile has its own model. The chat profile runs with a small 4b model for fast responses. The pro profile uses a 9b model for more complex tasks. The ultra profile uses the 27b model for deep analysis. This leads to different latency and quality profiles depending on the use case.
Phase 4: The Memory System
An agent without memory is just a chatbot. Every session starts from scratch, knows no history, and remembers nothing.
The memory system in Algroveon-Agent has two levels:
Level 1 – Recent Context: When starting a new session, the last messages from the previous session are loaded. This provides conversational continuity without overloading the context window.
Level 2 – Long-Term Memory: After logging out, a session summarizer summarizes the completed session in a maximum of five sentences. This summary is stored as a long-term memory item and inserted as a context header during the next login.
The hybrid retrieval combines SQLite full-text search with vector similarity search via Ollama embeddings. This is not a database framework – it is direct SQL with numpy for cosine similarity.
The difficult part: preventing memory poisoning. If the agent visits a website that contains instructions in its content ("forget everything previous and..."), this should not go into the persistent memory. The solution is the SourceTag system: anything with an EXTERNAL tag does not enter long-term memory without explicit user confirmation, regardless of what the model suggests.
Phase 5: HeadlessRunner and the Morning Briefing
An agent that only reacts to requests is a reactive system. It becomes interesting when it also acts proactively.
The HeadlessRunner enables tasks without an active browser user: the same policy logic, the same audit layer, but no external HTTP request required. An internal scheduler triggers tasks based on time.
The first practical result: a daily morning briefing via email. Weather, calendar preview for the next few days, configurable news feeds from RSS sources. What was required here: structured data (weather, calendar appointments) must not simply be interpreted by the LLM – otherwise, hallucinations occur. The solution is direct extraction from tool outputs in Python before the LLM formulates the body text.
The HeadlessRunner is now also the basis for planned messenger integration. The architecture is in place – a Telegram webhook would be a new route plus a mapping of external user IDs to internal user IDs.
Phase 6: The Web UI
Algroveon-Agent has a full browser interface, built with FastAPI, HTMX, and the Tabler CSS framework – hosted entirely locally, no external CDN.
Eight UI areas: Chat session, session overview, approval center, memory management, tool reference, diagnostics, settings, and an admin area for user management. All pages are server-side rendered – no JavaScript framework, no build step.
What worked well: HTMX for the SSE stream. The chat stream runs via Server-Sent Events. An initial HTTP request saves the user message and immediately returns a response: a user bubble in the HTML plus a placeholder div with an SSE connection attribute. A second GET request opens the stream, drives the agentic loop, and replaces the placeholder via hx-swap="outerHTML" with the finished response.
This results in reactive streaming behavior without a single line of frontend JavaScript for the streaming part.

Phase 7: Algroveon Mac
The browser UI is complete, but on the desktop, I wanted more: a menu bar icon, native notifications for approval requests, and chat without a browser tab.
Algroveon Mac is a pure SwiftUI app without third-party dependencies. The core idea: the Mac is not a second AI system, but a local tool executor. The LLM runs on the home server. The Mac handles macOS-native actions: calendar via EventKit, addresses via Contacts, Keychain for token storage.
The communication protocol between the Mac client and the server uses WebSockets with HMAC-signed messages. The server dispatches tool calls to the registered client, the client executes them and sends the result back. Replay protection via a ring buffer of dispatch IDs and an expires_at field prevents old dispatches from being replayed.
What I learned
Agentic systems are not difficult because the LLM is bad. They are difficult because of orchestration: multi-turn loops that break out. Tool calls from thinking blocks that are mistakenly recognized. Memory poisoning via external content. Approval waits that block within the stream context.
Each of these problems is solvable – but each requires its own logic, and every solution has its own edge cases.
The profile system as a central configuration layer was one of the best early decisions. The policy engine as a deterministic security layer too. Without an awareness of these problems, I might not have built both this way from the start.
What is still missing: RAG for large documents (foundation exists), voice interface, messenger integration. That will come – the big leap in architecture and security model has been made.